Real-Time Model Validation with Stream Partitioning
Partition streaming sports data and apply temporal validation to keep live predictive models accurate, low-latency, and resilient to drift.

Want to keep your predictive models accurate while processing live sports data in real time? Stream partitioning can be the key to achieving this. Here's why it matters and how it works:
- Real-time validation identifies errors early, saving costs and preventing flawed predictions. Catching issues in real time can be 10x cheaper than fixing them later.
- Stream partitioning divides data streams into smaller segments for faster processing, reduced latency, and dynamic scaling during high-traffic events like simultaneous games.
- Three main partitioning methods:
- Key-based: Groups related data (e.g., by game ID) but risks bottlenecks during popular events.
- Time-based: Organizes by intervals for easier historical queries but may disrupt live data order.
- Round-robin: Balances load evenly but requires reorganization for grouped data downstream.
- Validation techniques like hold-out partitioning, rolling validation, and time-series splits ensure accuracy while handling evolving data patterns.
Key takeaway: Stream partitioning enhances predictive accuracy and efficiency in fast-paced environments like sports betting. Tools like Apache Kafka and Flink make implementation possible, ensuring smooth operations even during peak loads.
Read on to learn how to apply these methods effectively.
Streaming Event-Time Partitioning With Apache Flink and Apache Iceberg - Julia Bennett

Stream Partitioning Basics
Stream Partitioning Methods Comparison for Real-Time Model Validation
What is Stream Partitioning?
Stream partitioning involves dividing a continuous data stream into multiple parallel substreams while maintaining the order of events. Think of it like splitting a busy highway into several lanes, where each lane processes its own sequence of vehicles. Each substream operates with its own clock and timestamps, which allows independent watermark calculations. This setup prevents issues like "timestamp interference" that can occur when clocks are misaligned - for example, when one game feed lags behind another.
"Partitioning is essential for scenarios where different entities in a stream have unaligned clocks or timestamps." - Timeplus Documentation
The real advantage of partitioning lies in parallel processing. With more partitions, more consumers can handle data at the same time, resulting in increased throughput and reduced latency. Additionally, in downstream systems such as data warehouses, partitioning enables "query pruning", where irrelevant data files are skipped entirely during searches, making queries much faster.
Grasping this foundational concept is a key step in enabling real-time model validation for streaming analytics. From here, we can explore the most commonly used partitioning methods and their practical applications.
Common Partitioning Methods
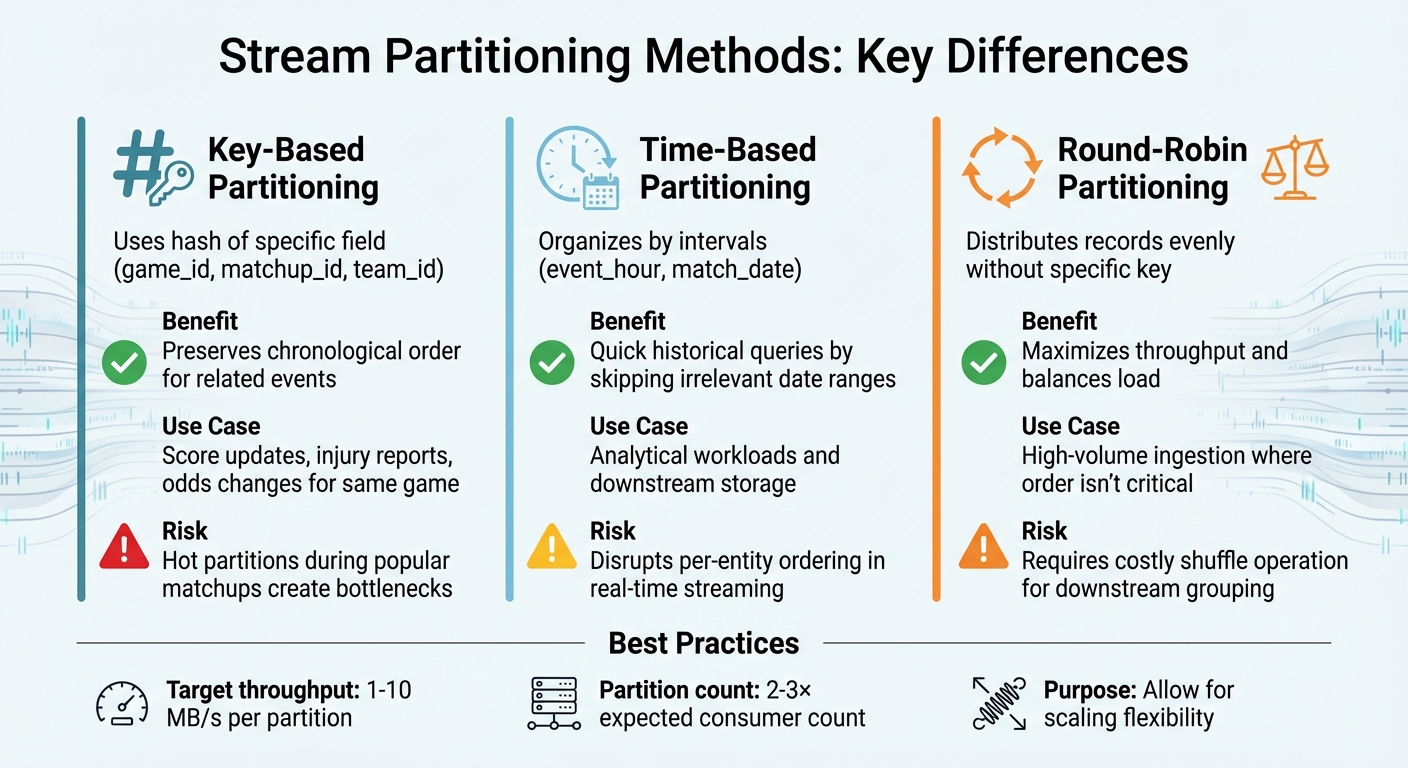
There are three main approaches to partition streaming data, each tailored to specific needs:
-
Key-based partitioning: This method uses a hash of a specific field, such as
game_id,matchup_id, orteam_id, to assign records to partitions. This ensures that all events related to a particular game - like score updates, injury reports, or odds changes - are routed to the same partition, preserving their chronological order. However, a popular matchup can lead to a "hot partition", where one partition becomes overloaded, creating a bottleneck for the pipeline. -
Time-based partitioning: Here, data is organized by intervals, such as
event_hourormatch_date. This approach is particularly useful for analytical workloads, as it allows quick querying of historical data by skipping irrelevant date ranges. That said, using time as the primary partition key in real-time streaming can disrupt per-entity ordering, making it more suitable for downstream storage rather than live processing. - Round-robin (or "sticky") partitioning: This method distributes records evenly across all partitions without relying on a specific key. It’s great for maximizing throughput and balancing the load, especially in high-volume ingestion scenarios where maintaining order isn’t critical. The trade-off? If downstream models need to group data by a specific field later, you’ll face a costly "shuffle" operation to reorganize the stream. As a general guideline, aim for 1–10 MB/s throughput per partition and set the partition count to be 2–3 times the number of expected consumers to allow for scaling.
Partitioning Methods for Real-Time Model Validation
Real-time model validation calls for partitioning methods that prioritize both precision and efficiency. With streaming data arriving continuously, traditional validation techniques often fall short and require adjustments to handle the dynamic flow effectively.
Hold-Out Partitioning for Live Data
Hold-out partitioning is straightforward: a portion of the data (usually 20–40%) is set aside for testing, while the rest is used for training. For example, in sports betting, you might train your model on the first 60% of a season's games and use the remaining 40% for validation. This approach is quick to implement and computationally light.
However, relying on a single split can be risky. If the test data contains anomalies - like a series of unexpected upsets or weather-related delays - it could skew results. To address this, you can introduce a gap size between training and test sets, ensuring independence by excluding a specific range of data (e.g., the last week of games). For historical streams, you might use "Latest" sampling to reflect current conditions or "Random" sampling to assess overall model stability.
Now, let’s look at how k-fold cross-validation can be adapted for streaming data.
Adapting K-Fold Cross-Validation for Streams
Traditional k-fold cross-validation requires multiple model re-fits, making it unsuitable for fast-moving data streams. Additionally, streaming data often experiences concept drift, where data patterns evolve over time, rendering static folds ineffective. As the data grows, the best hyperparameters may also shift, which means a fixed set chosen through standard cross-validation might not stay optimal.
Weighted Rolling Validation (wRV) offers a solution by using the next data point as the validation sample, keeping computational demands low. Another popular method is prequential evaluation, where each new data instance is first used for testing and then immediately for training. This approach aligns seamlessly with the natural flow of streaming data.
| Feature | Traditional K-Fold CV | Rolling Validation |
|---|---|---|
| Computational Cost | High (requires multiple re-fits) | Low (validates on the next point) |
| Handles Concept Drift | No (static folds) | Yes (adapts to new patterns) |
| Best Use Case | Offline hyperparameter tuning | Real-time model monitoring |
Lastly, time-series splits offer another way to maintain predictive accuracy.
Time-Series Splits for Predictive Accuracy
When dealing with time-dependent data, preserving temporal order is critical. Time-series splits ensure that training data always comes before test data, avoiding "future data leakage", where future information inadvertently influences past predictions.
A walk-forward (or "backtesting") approach is often used here: train the model on all games up to a specific date, validate it on the next batch of games, and then roll the window forward to repeat the process. This method is particularly effective for estimating real-world performance metrics like return on investment (ROI) and maximum drawdown, as it closely mimics how the model would operate in practice.
Performance Analysis of Partitioning Methods
Selecting the right partitioning method can have a direct impact on how well a model performs. Each approach comes with its own trade-offs in terms of accuracy, scalability, and complexity.
Comparing Partitioning Strategies
Now that we've covered the basics, let's dive into how different partitioning strategies perform. Hold-out partitioning stands out for being simple and computationally efficient. On the other hand, time-series splits are better suited for scenarios where data changes over time, as they maintain the temporal order and avoid look-ahead bias. However, this approach often requires more frequent model retraining, which can slow down real-time processes.
| Partitioning Strategy | Accuracy/Reliability | Scalability | Implementation Ease | Data Leakage Risk |
|---|---|---|---|---|
| Hold-Out | Moderate (depends on split) | High | Very Easy | Low (if chronological) |
| Standard K-Fold | Low (high leakage risk) | High | Very Easy | High (in time-series) |
| Walk-Forward | High (respects time) | Low (requires refitting) | Moderate | Very Low |
| Purged K-Fold | High | Moderate | Difficult | Low |
| Prequential | Medium (real-time) | High | Moderate | Low |
For meaningful backtests, it's recommended to use at least 100 training rows and 20 validation rows. Additionally, introducing a gap of 1 to 7 days between training and validation sets is a common practice. This gap helps account for deployment delays and minimizes the risk of data leakage.
Research Findings from Predictive Modeling
Empirical studies provide further insights into how these strategies affect model performance. For instance, RMSE is often preferred over MSE in real-time applications because it shares the same units as the target variable. This makes it easier for experts to interpret error magnitudes in areas like energy forecasting or betting odds.
When working with large streaming datasets, sampling 10–50% of data over a specific time window is a practical way to capture seasonal patterns without overwhelming memory resources during validation. In fields like sports betting, calibration - how well predicted probabilities match actual outcomes - can be more important than pure accuracy. Metrics like the Sharpe ratio, maximum drawdowns, and ROI are particularly useful for evaluating models in live markets, as they provide a better sense of risk and profitability compared to traditional error measures like RMSE or MSE.
Implementing Partitioning in Real-Time Streaming Pipelines
Scalable Partitioning for Streaming Frameworks
To implement partitioning in real-time streaming frameworks like Apache Kafka or Apache Flink, careful planning is essential to balance throughput and consumer scalability. In Kafka, aim for partitions that can handle between 1–10 MB/s of throughput to ensure smooth operation under heavy loads. When setting up your pipeline, start with a partition count that's 2–3 times your expected consumer count. This approach provides flexibility for scaling without the need for complex repartitioning later on.
However, challenges such as hot partitions can arise, especially in scenarios like sports betting analytics. For example, during major championship games, a surge in bets can overwhelm a single partition. To prevent this, use sub-partitioning by adding a hashed sub-key to your entity ID, which helps distribute the load more evenly across multiple consumers. Additionally, monitor lag asymmetry by setting alerts for when the ratio of max lag to average lag exceeds 5. This can help you address potential overloads early and rebalance consumer groups as needed.
In Flink, side-output routing through ProcessFunction offers an efficient way to handle invalid data by redirecting it to a Dead Letter Queue (DLQ) for further auditing. Meanwhile, valid data can continue seamlessly to your predictive models. To ensure data integrity, implement multiple validation layers, including schema checks for structural accuracy, range validation to confirm values like odds are positive, and business rule checks to catch logical errors.
By combining these partitioning strategies with strong monitoring practices, you can enhance the reliability and performance of real-time streaming pipelines, as demonstrated by WagerProof's implementation.
WagerProof Integration for Model Monitoring
WagerProof effectively uses these partitioning techniques to monitor and refine its sports betting prediction models. WagerProof's AI research agents continuously oversee partitioned streams, quickly identifying anomalies or opportunities like mismatched market spreads or high-value bets. These agents rely on stateful processing to track key metrics such as PSI (Population Stability Index) and ECE (Expected Calibration Error). If ECE exceeds twice the target threshold, the system automatically halts the affected model to prevent inaccurate predictions.
WagerProof's architecture maintains sub-100 ms latency while processing millions of events per second. This low latency is crucial during live games when betting odds shift rapidly. Additionally, WagerBot Chat connects directly to these partitioned streams, pulling in real-time updates like weather conditions, injury reports, and live model predictions. This ensures that recommendations are based on the most current data, reducing the risk of decisions based on outdated information.
Optimizing Sports Betting Models Through Partitioning
Tuning Partition Sizes for Model Accuracy
Getting the right balance between validation and training data is crucial for fine-tuning dynamic betting models. The challenge lies in reserving enough data for validation to ensure reliable testing, while still leaving plenty for training. In the fast-paced world of sports betting - where odds shift rapidly and team conditions change often - using robust temporal validation methods is key.
One critical step is ensuring that outdated or flawed data doesn’t throw off predictions. A technique called side-output routing helps with this by isolating problematic data points, like odds that fall outside expected ranges or incomplete injury reports. By diverting these errors, you prevent them from skewing your model’s accuracy.
When working with large datasets, precision becomes even more important. For instance, if you run 10,000 simulations with a probability of 0.5, the standard error is about 0.005. This level of detail helps you determine whether differences in partitioning strategies are real or just random noise.
To keep your model performing at its best, it’s not just about finding the perfect partition sizes - it’s also about ongoing monitoring and adjustments.
Using WagerBot Chat for Performance Tracking
Once your partitioning strategy is in place, tools like WagerBot Chat can take your model monitoring to the next level. WagerBot Chat connects directly with WagerProof's live data streams, giving you real-time insights into how your partitioning choices are affecting model performance.
Instead of digging through databases or setting up custom dashboards, you can simply ask questions like, “How did the NBA model perform on yesterday’s games compared to last week?” WagerBot Chat will provide a detailed breakdown, including partition-specific accuracy rates and any potential data quality issues. This kind of instant feedback not only saves time but also gives you a clearer picture of how your decisions are influencing real betting results.
Conclusion
By leveraging the partitioning strategies and real-time monitoring techniques we've discussed, this approach reshapes how model validation is handled. Partition keys, like game_id, ensure match events are processed sequentially while maintaining sub-second latency - a critical factor for staying aligned with fast-changing market dynamics.
The cost benefits are hard to ignore. Identifying and addressing malformed data within the streaming pipeline is 10x cheaper than fixing issues after corruption occurs. For sports like basketball, where hundreds of updates can flood in during a single game, partitioned ingestion spreads the workload across multiple nodes, avoiding bottlenecks and ensuring smooth operation.
This method also strengthens model dependability in live environments. By halting execution automatically if the Expected Calibration Error (ECE) surpasses twice the target threshold, you avoid deploying models that could compromise market coherence.
WagerProof exemplifies these principles through its AI-powered research agents and live data infrastructure. With access to real-time streams, the platform ensures that personalized agents validate predictions against actual game outcomes as events unfold - not hours later. Additionally, WagerBot Chat allows users to query model performance effortlessly in plain English, delivering insights into validation metrics, data quality checks, and partition-specific accuracy rates - all without the need for manual database queries.
Together, these tools and techniques lay the groundwork for predictive models that adapt quickly, fail safely, and consistently maintain their competitive edge in sports betting.
FAQs
How do I choose the right partition key for live sports data?
To select the best partition key for live sports data, prioritize even load distribution and preserving the order of events. High-cardinality keys, such as player IDs or match IDs, work well to prevent overloading specific partitions. Keep related events that need to maintain a sequence within the same partition. Steer clear of low-cardinality keys or those that distribute data unevenly. Regularly monitor partition performance and make adjustments when necessary to ensure smooth and reliable streaming.
How can I validate a model in real time without data leakage?
To ensure a model is validated in real time without risking data leakage, it's crucial to maintain the natural temporal order of the data. Avoid actions like random shuffling, as they can disrupt this sequence. Instead, use methods such as rolling windows or expanding windows, which allow you to split training and validation sets in a way that respects the chronological flow.
Additionally, implementing real-time checks can help maintain data integrity. These checks might include:
- Schema validation: Ensuring the structure and format of incoming data match expectations.
- Business rule enforcement: Verifying that the data aligns with predefined business logic.
- Anomaly detection: Identifying and addressing unusual patterns that could indicate errors or inconsistencies.
These practices help safeguard the model from future data influencing past predictions, preserving its reliability and accuracy.
What should I monitor to detect hot partitions and concept drift fast?
To stay ahead of hot partitions and concept drift, it's important to keep an eye on distributional shifts in probability integral transforms. Tools like PITMonitor can help with this by providing calibration-specific, anytime-valid monitoring. What makes it stand out? It includes formal error guarantees and uses Bayesian changepoint detection to spot when distributions change.
Another useful approach is analyzing error rates through optimal sub-windows, such as OPTWIN. This method helps pinpoint statistically significant differences, which can act as clear indicators of drift. Together, these tools make it easier to detect and respond to shifts effectively.